War stories - Network changes tools
Network changes tool to prevent disasters.
Network changes
Every time I manage a change to a customer network I have a chance to taste the many shades of possible IT Operations maturity levels .
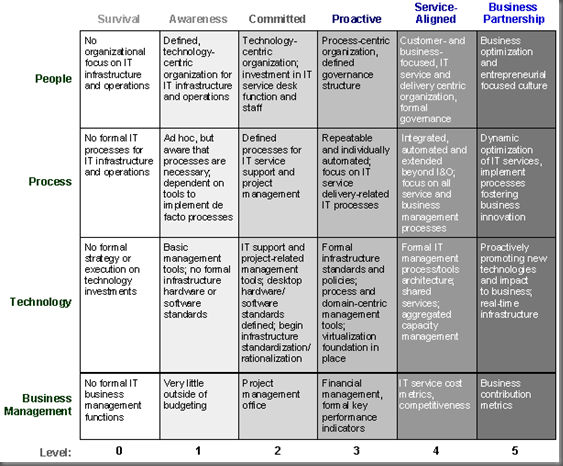
I collected some best practices over the years about how to reduce risk and speed-up the change and testing process. I’ll share some in this post.
Improvements and suggestions are welcome in the comments of the post or on my Twitter account .
Phase 1: collect data
The first step is to collect all the available information, including:
- configuration of all devices
- network topology, physical and logical
- create a local user to access devices if radius/tacacs is unreachable during the change
- verify device logs
- send all device logs to a syslog
If the customer doesn’t use a Syslog server (after being strongly advised to do so) I install one. PRTG or a [container with Syslog-ng](container with Syslog-ng) are good options.
Some state information are not present in the running configuration so the output of dynamic states should be saved too, examples are:
- arp table
- mac-address table
- routing table
- routing process tables: ospf database / eigrp topology / bgp table
- NAT entries
There are many tools to collect the data other than the CLI: Ansible , Napalm , Nornir and TextFSM . My preferred tool is netmiko-show that collects data and saves the output in text files. Pick the one you’re more comfortable with.
Collect all the ping and traceroute output from multiple locations. These will be used later to validate the change outcome.
Phase 2: the change
I won’t discuss the details of the actual change commands here but will only discuss the methods.
I’m not a fan of ITIL or other change averse cultures but some documents should be created to improve the chances of success.
Apply Pareto and pragmatism. Creating too many documents leads to a big overhead and risk to lose focus on the actual operations.
Change documents should include at least:
Detailed description of changes
Plan your work, work your plan. The description should include every command on every device, every cable that need to be added, moved or disconnected, everything.
Collect the status of the network before the change
This is where Phase 1 helps. Sometimes in the middle of the change operations someone asks “was it like this before?" or even worse “did it worked before?".
The Mean Time to Innocence is reduced if the behavior of the network before the change is well documented.
An example of a recent event: while changing the routing preferences the customer complained that he couldn’t ssh to some devices. It took more than an hour to their firewall guy to admit that ssh to those boxes was disabled weeks before. Not funny.

For every change describe what expect and to test before, during and after the change
This is what I learned during my CCIE studies and it is crucial to avoid long troubleshooting sessions. Skills and experience work together here to fully understand the impact of the changes.
Tools like VIRL , GNS3 and EVE-NG allow to create labs and try the changes in a test environment. Of course these are limited tools when multiple devices are involved and they can’t all be simulated but they can help.
Remember to log everything: Putty and SecureCRT can record all the session output to a text file. If you use Linux use tee .
Another recent example: during the routing change the customer wanted to add a last minute redundancy test, shutting down the DWDM links between two sites. I knew well how OSPF was configured and how it was expected to converge. Result: one ping lost. 10/21/2018 10:34:05 AM bGreat!
The tools
The tools that I use are usually based on the time and budget of the project. For some major changes I had a chance to deploy a distributed SmokePing and some Icinga2 nodes across the network to verify the status before, during and after the change. This takes time do design and implement, sometimes a tool that is ready to use is preferred - the usual build or buy dilemma.
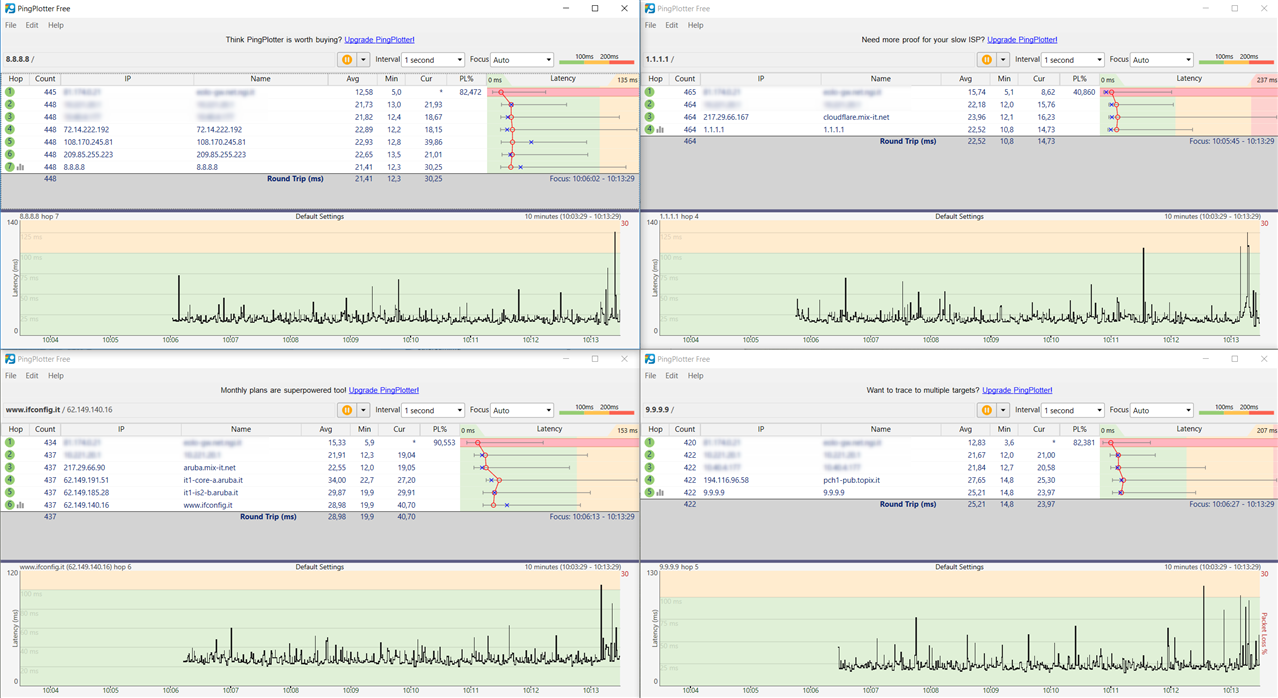
A tool I like is PingPlotter from PingManTools .
The Free version is fine and the Pro version has a remote agent feature that allows to measure the connection from multiple points at the same time.
Another product from PingManTools very useful (and cheap) is MultiPing . Multiping allows to ping multiple destinations
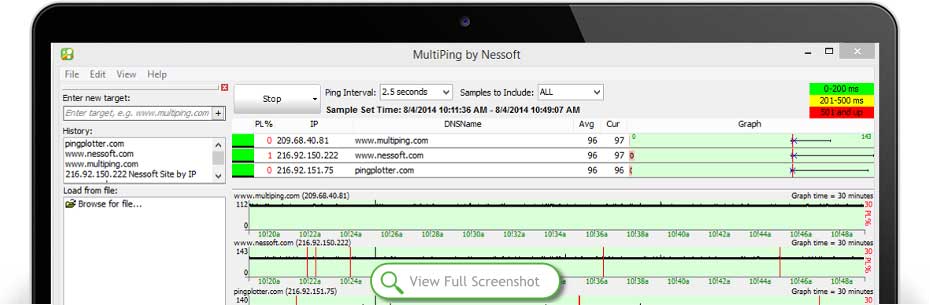
If you’re in a budget (really? MultiPing costs 40 bucks!) there are some free alternatives like PingInfoView , search AlternativeTo.net for more.
Linux users can use MTR as an alternative but it misses the GUI and nice colors of MultiPing .
The workflow
So how to use these tools during a change?
For example put multiple PingPlotter instances in one or more virtual desktops, based on the use. On a Linux shell use tmux and run MTR to one target per section.
Switching between virtual desktop is fast and keeps multiple windows organized. One desktop can be dedicated to wan links, another for lan devices.
This is how it looks like:
During the change on the first desktop I start SecureCRT , Notepad++ and the change document procedure to follow and to take notes.
Remember to log all session output on text files, it is very useful to create a post-change (or post-mortem) document. After the change I usually read the logs to look for improvement or errors.
A tool to quick search text file on Windows is GLOGG . On Linux a grep will suffice. Much better than searching in notepad.
Spot changes
During the changes it is crucial to have a quick feedback of what’s happening on the networks.
How to spot the changes? Running a debug on devices and keeping track of Syslog messages helps for sure but sometimes are not enough.
If you use any tool to get device states in text format like netmiko-show during the migration then diff software like Meld and WinMerge can help.
On Linux (or WSL ) a simple diff will be enough
diff -r d1 d2
Just remember to clean the output from any date/time of variable information that may create some confusion (sed is your friend).
Example: for a datacenter network migration I put all the VMs and servers MAC addresses on a list and created a quick script to the VLAN association for each MAC. When a VM was moved to the new VLAN the list was updated. The migration was done when all the MAC addresses were in the new VLAN.
Wrap up
In this post I just scratched the surface of the many methods and tools available to make our life as network engineers easier and reduce the stress.
I try to use the best tool for the job, giving priority to pragmatism and efficiency, staying away from over-engineering.
I teach my mentees that a ping on a CLI is not the most efficient and complete validation tool for a change. We deserve better.
Somebody may argue that Intent Based Networking will make out life easier. I think the road to automation of changes and testing is long ad will take some time, measured in years. In the meantime we should learn to use better tools and learn Python along the way.
I hope you can find something useful in this post. I would really like some feedback to know the tools and methods you use, there is always room for improvement and I enjoy to test new tools.